Randomisierte Algorithmen
Contents
Randomisierte Algorithmen
- Definition
- Randomisierte Algorithmen sind Algorithmen, die bei Entscheidungen über das weitere Vorgehen oder bei der Wahl der Parameter Zufallszahlen benutzen.
Anschaulich gesprochen, wersucht man bei randomisierten Algorithmen, einen Teil der Lösung zu raten. Auf den ersten Blick würde man vermuten, dass dabei nicht viel Sinnvolles herauskommen kann. Diese Kapitel wird jedoch zeigen, dass man durch geschicktes Raten tatsächlich zu sehr eleganten Algorithmen gelangen kann.
Grundsätzlich unterscheidet man zwei Arten von randomisierten Algorithmen:
- Las Vegas - Algorithmen
- Das Ergebnis des Algorithmus ist immer korrekt, und die Berechnung erfolgt mit hoher Wahrscheinlichkeit effizient.
- Monte Carlo - Algorithmen
- Die Berechnung ist immer effizient, und das Ergebnis ist mit hoher Wahrscheinlichkeit korrekt.
Las Vegas-Algorithmen verwendet man, wenn der Algorithmus im ungünstigen Fall eine schlechte Laufzeit hat, und der ungünstige Fall kann durch die Randomisierung sehr unwahrscheinlich gemacht werden. Wir haben in der Vorlesung schon mehrere Las Vegas-Algorithmen kennen gelernt:
- Quick Sort mit zufälliger Wahl des Pivot-Elements: Die Randomisierung verhindert, dass das Array immer wieder in Subarrays von sehr unterschiedlicher Größe aufgeteilt wird.
- Treap mit zufälligen Prioritäten: Die Randomisierung verhindert, dass der Baum schlecht balanciert ist.
- Universelles Hashing: Die zufällige Wahl der Hashfunktion verhindert, dass ein Angreifer eine Schlüsselmenge mit sehr vielen Kollisionen konstruieren kann.
- Erzeugung einer perfekten Hashfunktion: Durch die Randomisierung entsteht mit nach wenigen Versuchen ein zyklenfreier Graph, der zur Definition der Hashfunktion geeignet ist.
Monte Carlo-Algorithmen verwendet man dagegen, wenn kein effizienter deterministischer Algorithmus für ein Problem bekannt ist. Man gibt sich dann damit zufrieden, dass der randomisierte Algorithmus die korrekte Lösung nur mit hoher Wahrscheinlichkeit findet, wenn dies dafür sehr effizient geschieht. Bei manchen Problemen ist auch dies unerreichbar - man muss dann bereits zufrieden sein, wenn der Algorithmus mit hoher Wahrscheinlichkeit eine sehr gute Näherungslösung findet. Beliebte Anwendungsgebiete für Monte Carlo-Algorithmen sind beispielsweise
- Randomisierte Primzahl-Tests: Moderne Verschlüsselungsverfahren benötigen zahlreiche Primzahlen, aber exakte Primzahltests sind teuer. Der Miller-Rabin-Test findet effizient Zahlen, die mit sehr hoher Wahrscheinlichkeit tatsächlich Primzahlen sind.
- Randomisiertes Testen: Wie jeder Test kann auch eine randomisierter Test nicht die Abwesenheit von Programmierfehlern garantieren, aber man kann durch die Randomisierung viel mehr Testfälle generieren und erhöht so die Erfolgswarscheinlichkeit. Wir haben als Beispiel dafür den Algorithmus von Freivald behandelt.
- Lösung schwieriger Optimierungsprobleme: Wir zeigen unten, dass ein randomisierter Algorithmus effizient eine Lösung für das 2-SAT-Problem aus dem vorherigen Kapitel findet (für k-SAT mit
 liefert der Algorithmus immer noch mit einer gewissen Wahrscheinlichkeit das richtige Ergebnis, ist aber nicht mehr effizient). Einen effizienten Approximationsalgorithmus für des Problem des Handelsreisenden behandlen wir im Kapitel NP-Vollständigkeit. Weitere wichtige Beispiele für diesen Bereich sind simulated annealing und das Markov-Chain-Monte-Carlo-Verfahren.
liefert der Algorithmus immer noch mit einer gewissen Wahrscheinlichkeit das richtige Ergebnis, ist aber nicht mehr effizient). Einen effizienten Approximationsalgorithmus für des Problem des Handelsreisenden behandlen wir im Kapitel NP-Vollständigkeit. Weitere wichtige Beispiele für diesen Bereich sind simulated annealing und das Markov-Chain-Monte-Carlo-Verfahren. - Robuste Statistik: Eine Grundaufgabe der Statistik ist das Anpassen (Fitten) von Modellen an gemessene Werte. Wenn die Messungen jedoch "Ausreißer" (einige völlig falsche Werte) enthalten, geht die Anpassung schief. Wir beschreiben unten den RANSAC-Algorithmus, der die Ausreißer identifizieren und beim Modellfitten ignorieren kann.
Anwendung: Lösen des K-SAT-Problems
geg.: logischer Ausdruck in K-CNF (n Variablen, m Klauseln, k Variablen pro Klausel)

for i in range (trials): #Anzahl der Versuche
#Bestimme eine Zufallsbelegung des  :
for j in range (steps):
if erfüllt alle Klauseln: return
#wähle zufällig eine Klausel, die nicht erfüllt ist und negiere zufällig eine der Variablen in dieser Klausel
(die Klausel ist jetzt erfüllt)
return None
:
for j in range (steps):
if erfüllt alle Klauseln: return
#wähle zufällig eine Klausel, die nicht erfüllt ist und negiere zufällig eine der Variablen in dieser Klausel
(die Klausel ist jetzt erfüllt)
return None
Eigenschaft: falls 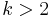 : steps *trials
: steps *trials 
z.B.  steps=3*n, trials=
steps=3*n, trials=
aber: bei  sind im Mittel nur steps=
sind im Mittel nur steps= nötig, trials=
nötig, trials=
-Zufallsbelegung hat  richtige Variablen (im Mittel
richtige Variablen (im Mittel  )
)
Negieren einer Variable ändert t um 1,
u.Z.  mit Wahrscheinlichkeit
mit Wahrscheinlichkeit  ::(für beliebiges k:
::(für beliebiges k:  )
)
 mit Wahrscheinlichkeit ::(für beliebiges k:
mit Wahrscheinlichkeit ::(für beliebiges k:  )
)
-Wieviele Schritte braucht man im Mittel, um zu einer Lösung mit t Richtigen zu kommen?

#Abbruchbedingung der Schleife

Probe:

Das ist das Random Walk Problem
Im ungünstigsten Fall (t=0) werden im Mittel  Schritte benötigt, um durch random walk nach t=n zu gelangen.
Schritte benötigt, um durch random walk nach t=n zu gelangen.
2. RANSAC-ALGORITHMUS (Random Sample Consensus)
Aufgabe: gegeben: Datenpunkte
- gesucht: Modell, das die Datenpunkte erklärt

Messpunkte:
übliche Lösung: Methode der kleinsten Quadrate
 Schulmathematik:
Schulmathematik: 
Lineares Gleichungssystem









- Problem:
 der Datenpunkte sind Outlier
der Datenpunkte sind Outlier
 Einfaches Anpassen des Modells an die Datenpunkte funktioniert nicht
Einfaches Anpassen des Modells an die Datenpunkte funktioniert nicht
- Seien mindestens k Datenpunkte notwendig, um das Programm anpassen zu können
RANSAC-Algorithmus
for l in range (trials):
wähle zufällig k Punkte aus
passe das Modell an die k Punkte an
zähle, wieviele Punkte in der Nähe des Modells liegen (d.h.  muss geschickt gewählt werden)
#Bsp. Geradenfinden:-wähle a,b aus zwei Punkten
-berechne:
muss geschickt gewählt werden)
#Bsp. Geradenfinden:-wähle a,b aus zwei Punkten
-berechne:  -zähle Punkt i als Inlier, falls
-zähle Punkt i als Inlier, falls  return: Modell mit höchster Zahl der Inlier
return: Modell mit höchster Zahl der Inlier
mit k=Anzahl der Datenpunkte und p=Erfolgswahrscheinlichkeit,
=Outlier-Anteil
Erfolgswahrscheinlichkeit: p=99%

Ein Spiel: Wie viel Schritte braucht man im Mittel zum Ziel?
geg.: 5 Plätze, 2 Personen: eine Person rückt vom einem Platz zu dem enderen Platz;
die zweite Person wirft die Münze.
Wenn die Münze auf Kopf landet, rücke nach rechts und wenn die Münze auf Zahl landet, rücke nach links.
<--- Zahl Kopf-->
Kopf: /////
Zahl: ///
- => mit 8 Schritten bis zum Ziel
- im Mittel: bei N Plätzen braucht man N2 Schritte
- all: mit N2 Schritten um N Plätze rücken
- Wie viel Schritte braucht man im Mittel zum Ziel?
#wenn wir uns im Stuhl Nr.1 befinden

#bei 0.Platz
- Lösung:

- speziell:
#wenn man am ungünstigsten Platz startet
Beziehung zu randomisiertem 2-SAT
"Platz":
sind falsch gesetzt

# Anfangszustand
Las Vegas vs. Monte Carlo
* Las Vegas - Algorithmen
- Ergebnis ist immer korrekt.
- Berechnung ist mit hoher Wahrscheinlichkeit effizient (d.h. Randomisierung macht den ungünstigsten Fall unwahrscheinlich).
* Monte Carlo - Algorithmen
- Berechnung immer effizient.
- Ergebnis mit hoher Wahrscheinlichkeit korrekt (falls kein effizienter Algorithmus bekannt, der immer die richtige Lösung liefert).
| Las Vegas | Monte Carlo |
|---|---|
| - Erzeugen einer perfekten Hashfuktion | - Algorithmus von Freiwald(Matrizenmultiplikation) |
| - universelles Hashing | - RANSAC |
| - Quick Sort mit zufälliger Wahl des Pivot-Elements | - randomisierte K-SAT(k>=3)(Alg. von Schöning) |
| - Treep mit zufälligen Prioritäten | - |
Zufallszahlen
- - kann man nicht mit deterministischen Computern erzeugen
- - aber man kann Pseudo-Zufallszahlen erzeugen, die viele Eigenschaften von echten Zufallszahlen haben
- * sehr ähnlich zum Hash
"linear Conguential Random number generator"

![\begin{array}{ll}
\mathrm{=> } & I_i \in [0, m-1]\\
\end{array}](/images/math/5/1/9/519da382c2f43f423e613c7fed368f03.png)
- -sorgfältige Wahl von a, c, m notwendig
- Bsp. m = 232
- a = 1664525, c = 1013904223
- "quick and dirty generator"
- Bsp. m = 232
Nachteile
- nicht zufällig genug für viele Anwendungen
- Bsp. wähle Punkt in R3

- gibt Zahl u, v, w so, dass
![\begin{array}{ll}
\mathrm{ } & u * p[0] + v * p[1] + w * p[3]\\
\end{array}](/images/math/9/6/0/960e01e2ab8ade9a893810334ccbd371.png)
- stark geclustert ist.
- Periodenlänge ist zu kurz:
- spätestens nach m Schritten wiederholt sich die Folge
- allgemein: falls der interne Zustand des Zufallsgenerators k bits hat, ist Periodenlänge:

- lowbits sind weniger zufällig als die highbits
Mersenne Twister
bester zur Zeit bekannter Zufallszahlengenerator (ZZG)
- innere Zustand:

- Periodenlänge:

- Punkte aus aufeinanderfolgende Zufallszahlen in
 sind gleich verteilt bis
sind gleich verteilt bis 
- alle Bits sind unabhängig voneinander zufällig ("Twister")
- schnell
class MersenneTwister:
def __init__(self, seed):
self.N = 624 # Größe des inneren Zustands festlegen
self.i = 0 # zählt mit in welchem Zustand wir uns gerade aufhalten
self.state = [0]*self.N # Speicher für den inneren Zustand reservieren
self.state[0] = seed # initiale Zufallszahl vom Benutzer
# den Rest des inneren Zustands mit einfachem Zufallszahlengenerator initialisieren
for i in xrange(1, self.N):
self.state[i] = (1812433253 * (self.state[i-1] ^ (self.state[i-1] >> 30)) + i) % 4294967296
def __call__(self):
"""gibt die nächste Zufallszahl im Bereich [0, 232-1] aus"""
N, M = self.N, 397
# Zustand aktualisieren (neue Zufallszahl ausrechnen)
i = self.i
r = ((self.state[i] & 0x80000000) | (self.state[(i+1)%N] & 0x7FFFFFFF)) >> 1
if self.state[(i+1)%N] & 1:
r ^= 0x9908B0DF
self.state[i] = self.state[(i+M)%N] ^ r
# aktuelle Zufallszahl auslesen und ihre Zufälligkeit durch verwürfeln der Bits verbessern
y = self.state[i]
y ^= (y >> 11)
y ^= ((y << 7) & 0x9D2C5680)
y ^= ((y << 15) & 0xEFC60000)
y ^= (y >> 18)
# Zustand weitersetzen und endgültige Zufallszahl ausgeben
self.i = (self.i + 1) % N
return y
geg.: Zufallszahl
![\begin{array}{ll}
\mathrm{ } & [0, \overbrace{2^{32}-1}^{m-1}]\\
\end{array}](/images/math/e/c/f/ecf19a2f71e4f83acbac7af0431485c7.png)
ges.: Zufallszahl
![\begin{array}{ll}
\mathrm{ } & [0, k - 1]\\
\end{array}](/images/math/8/f/d/8fd55ba9b8f50c5326a964bda677b254.png)
naive Lösung:  ist schlecht.
ist schlecht.
Bsp.

| rand() | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| rand()%k | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 0 | 1 | 2 | 3 | 4 |
=> 0,...,4 kommt doppelt so häufig wie 5,...,10 "nicht zufällig"
Lösung: Zurückweisen des Rests der Zahlen (rejektion sampling)

r = rand()
while r > last.GoodValue:
r = rand()
return r%k