Difference between revisions of "Sortieren"
(→Sortieralgorithmen: Gliederung... In wikis sind a), b), c) in Überschriften unüblich) |
(→3.4 Quicksort: Gliederung...) |
||
| Line 131: | Line 131: | ||
sortiert. | sortiert. | ||
| − | == 3.4 Quicksort == | + | === 3.4 Quicksort === |
* Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [http://de.wikipedia.org/wiki/C._A._R._Hoare] entwickelt. Es gibt viele Implementierungen von Quicksort, siehe vgl. [http://de.wikipedia.org/wiki/Quicksort]. | * Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [http://de.wikipedia.org/wiki/C._A._R._Hoare] entwickelt. Es gibt viele Implementierungen von Quicksort, siehe vgl. [http://de.wikipedia.org/wiki/Quicksort]. | ||
* Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren. | * Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren. | ||
| − | === | + | ==== Algorithmus ==== |
quiksort(l,r) ← { #l: linke Grenze, r: rechte Grenze des Arrays | quiksort(l,r) ← { #l: linke Grenze, r: rechte Grenze des Arrays | ||
| Line 146: | Line 146: | ||
} | } | ||
| − | === | + | ==== Algorithmus für <tt>partition</tt> ==== |
Aufgabe: Ordne <tt>a</tt> so um, dass nach der Wahl von <tt>i</tt> (Pivot-Element) | Aufgabe: Ordne <tt>a</tt> so um, dass nach der Wahl von <tt>i</tt> (Pivot-Element) | ||
| Line 194: | Line 194: | ||
Aufteilung für die Partitionen ergibt: | Aufteilung für die Partitionen ergibt: | ||
| − | # | + | # Erste Partition: <tt>[l,i-1]</tt>, zweite Partition: <tt>[i+1,r]</tt> |
| − | # | + | # Die erste Partition umfasst <tt>N-1</tt> Elemente |
| − | # | + | # Die zweite Partition ist leer (bzw. sie existiert nicht), weil das Pivot-Element <tt>p = r</tt> gewählt wurde. Das Array wird also elementweise abgearbeitet. |
| − | + | # → <tt>N</tt> einzelne Aufrufe ⇒ Zeitkomplexität: <math>\approx | |
| − | Pivot-Element <tt>p = r</tt> gewählt wurde. Das Array wird also elementweise | ||
| − | |||
| − | abgearbeitet. | ||
| − | # | ||
\frac{N^2}{2}</math> (siehe Berechnung vom 16.04.2008) | \frac{N^2}{2}</math> (siehe Berechnung vom 16.04.2008) | ||
# Für identische Schlüssel sollten beide Laufvariablen stehen bleiben. | # Für identische Schlüssel sollten beide Laufvariablen stehen bleiben. | ||
| − | # | + | # Bei der gegebenen Implementierung tauscht auch gleiche Elemente aus. |
# Für identische Schlüssel können die Abbruchbedingungen verbessert werden (siehe | # Für identische Schlüssel können die Abbruchbedingungen verbessert werden (siehe | ||
Sedgewick). | Sedgewick). | ||
| − | === | + | ==== Komplexität ==== |
<math>C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) | <math>C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) | ||
Revision as of 12:28, 28 April 2008
Contents
Headline text
Nebenbemerkung für die Hausaufgabe über die timeit-Bibliothek:
+--------+ +----+ setup = """ prog = """ | | --> |init| +----+ +----+ | | +----+ |init| |prog| | | +----+ +----+ | | +----+ """ """ | | --> |prog| +--------+ +----+
- Timeit-Objekt erzeugen: t = timeit.Timer(prog, setup)
- Frage: Wie oft soll die Algorithmik wiederholt werden
- z.B. N = 1000
- Zeit in Sekunden für N Durchläufe: K = t.timeit(N)
- Zeit für 1 Durchlauf: K/N
3.Stunde am 16.04.2008
Sortierverfahren
Motivation
Def: Ein Sortierverfahren ist ein Algorithmus, der dazu dient, eine Liste von Elementen zu sortieren.
Anwendungen
- Sortierte Daten sind häufig Vorbedingungen für Suchverfahren
(Speziell für Algorithmen mit Log Komplexität)
- Darstellung menschl. Wahrnehmung
- Bemerkungen
aus Programmiertechnischer Anwenwendungssicht hat das Sortierproblem an Relevanz verloren da
- Festplatten / Hauptspeicher heute weniger limitierenden Charakter haben
- gängige Proprammiersprachen haben typenabhängige Algorithmen zur Verfügung stellen.
Vorraussetzungen/ Spielregeln
2.1 Mengentheoretische Anforderungen
- Def
- Totale Ordnung/ Total gordnete Menge
Eine Totale Ordnung/ Total geordnete Menge ist eine binäre Relation
R \subseteq M \times M über einer Menge M.
Eigenschaften transitiv, antisymmetrisch und total
Hab in der Wiki eine gute Seite dazu gefunden Ordnungsrelation
Konkret
R sei dargestellt als infix Notationdann, falls M total geordet, gilt

(1)  (anitsymmetrisch)
(anitsymmetrisch)
(2)  (transitiv)
(transitiv)
(3)  (total)
(total)
Bemerkung: aus 3 folgt  (reflexiv)
(reflexiv)
Datenspeichen
a) Array (Grafik folgt noch)
b) Vekettete Liste
Nachteil Adressierung bsp: 10 > 9
Charakterisierung von Algorithmen
(a) Komplexität O(1), O(n), O(.), \Omega (.)
Rekursive Zerlegung zerlegt Ürsprüngliche Probleme in kleinere Probleme und wendet sie auf die kleineren Probleme an; daraufhin werden die Teilrobleme zur Lösung des Gesamtproblems verwendet. Aufwand für N Eingaben, hängt ab vom Aufwand der Eingaben geringeren Umpfangs ab. (Teilprobleme)
----
4. Stunde, am 17.04.2008
(Fortsetzung der Stunde vom 16.04.2008)
Mergesort
Algorithmus
- c ← merge(a,b) (Siehe Mitschrift der Stunde am 16.04.2008)
- rekursiver Mergesort:
mergesort(m) ← { #m ist ein Array
if |m| > 1 #True, wenn m mehr als 1 Element hat.
a ← mergesort(m[1:<|m|/2])
b ← mergesort(m[|m|/2-1:|m|])
c ← merge(a,b)
return(c)
else
return(m)
}
Bei der Sortierung mit Mergesort wird das Array immer in zwei Teile geteilt. → Es
entsteht ein Binärbaum der Tiefe  .
.
Zeitkomplexität: 
Komplexität
Komplexität:  (für N =
(für N = 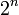 )
)
Erklärungen zur Formel:
-
 : für jede Hälfte des Arrays
: für jede Hälfte des Arrays -
 : für das Zusammenführen
: für das Zusammenführen
weitere Eigenschaften von MergeSort
- Mergesort ist stabil, weil die Position gleicher Schlüssel im Algorithmus
merge(a,b) nicht verändert wird - wegen „<” hat das linke
Element Vorrang.
- Mergesort ist unempfindlich gegenüber der Reihenfolge der Eingabedaten.
Grund dafür ist die vollständige Aufteilung des Ausgangsarrays in Arrays der Länge
1.
- Diese Eigenschaft ist dann unerwünscht, wenn ein Teil des Arrays oder gar das
ganze Array schon sortiert ist. Es wird nämlich in jedem Fall das ganze Array neu
sortiert.
3.4 Quicksort
- Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [1] entwickelt. Es gibt viele Implementierungen von Quicksort, siehe vgl. [2].
- Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren.
Algorithmus
quiksort(l,r) ← { #l: linke Grenze, r: rechte Grenze des Arrays
#Das Array läuft also von l bis r (a[l:r])
if r > l
i ← partition(l,r) #i ist das Pivot-Element
quicksort(l,i-1) #quicksort auf beide Hälfte des Arrays anwenden
quicksort(i+1,r)
}
Algorithmus für partition
Aufgabe: Ordne a so um, dass nach der Wahl von i (Pivot-Element)
gilt:
-
![a[i]](/images/math/5/9/5/595711c58954cfc2eb727cba561e3512.png) ist sortiert, d.h. dieses Element ist am endgültigen Platz.
ist sortiert, d.h. dieses Element ist am endgültigen Platz. -
![\forall x \in \left\{ a \left[ l \right] , ... a \left[ i-1 \right]
\right\} : x \leq a \left[ i \right]](/images/math/4/8/a/48aae1d8be4cea26da95b8ff77e40cd1.png)
-
![\forall x \in \left\{ a \left[ i+1 \right], ... a \left[ r \right]
\right\} : x \geq a \left[ i \right]](/images/math/a/d/c/adcbf0ffe4d766ad8401e1ba9086d5b8.png)
Abbildung fehlt noch a[i] heißt Pivot-Element (p)
i ← partition(l,r) ← {
p ← a[r] #p: Pivot-Element. Hier wird willkürlich das rechteste Element
# als Pivot-Element genommen.
i ← l-1 #i und j sind Laufvariablen
j ← r
repeat
repeat
i ← i+1 #Finde von links den ersten Eintrag >= p
until a[i] >= p
repeat
j ← j+1 #Finde von rechts den ersten Eintrag <= p
until a[j] <= p
swap(a[i], a[j])
until j <= i #Nachteile: p steht noch rechts
swap(a[i], a[j]) #Letzter Austausch zwischen i und j muss
#zurückgenommen werden
swap(a[i], a[r])
return(i)
}
Bemerkungen zur gegebenen Implementierung:
- Sie benötigt ein Dummy-Minimalelement.
- Dieses Element ist durch zusätzliche if-Abfrage vermeidbar, aber die
if-Abfrage erhöht die Komplexität des Algorithmus (schlechte Performanz).
- Sie ist ineffizient für (weitgehend) sortierte Arrays, da sich folgende
Aufteilung für die Partitionen ergibt:
- Erste Partition: [l,i-1], zweite Partition: [i+1,r]
- Die erste Partition umfasst N-1 Elemente
- Die zweite Partition ist leer (bzw. sie existiert nicht), weil das Pivot-Element p = r gewählt wurde. Das Array wird also elementweise abgearbeitet.
- → N einzelne Aufrufe ⇒ Zeitkomplexität:
 (siehe Berechnung vom 16.04.2008)
(siehe Berechnung vom 16.04.2008) - Für identische Schlüssel sollten beide Laufvariablen stehen bleiben.
- Bei der gegebenen Implementierung tauscht auch gleiche Elemente aus.
- Für identische Schlüssel können die Abbruchbedingungen verbessert werden (siehe
Sedgewick).
Komplexität
![C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k)
\right]](/images/math/8/5/0/8501ba6065bba57762180b2267ce066a.png) für
für 
Anmerkungen zur Formel:
-
 : Vergleiche für jeden Aufruf
: Vergleiche für jeden Aufruf -
 : Teilungspunkt
: Teilungspunkt
![\frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) \right] = 2 \frac{1}{N}
\sum_{k=1}^{N} C(k-1)](/images/math/c/3/0/c3035051266f59bfb6fd2d2d0b8c7b94.png)
![C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) \right]
\overset{\cdot N}{\longleftrightarrow}](/images/math/b/b/2/bb27677b46385665077a41bf199494ca.png)
![N \cdot C(N) = N \left[ (N+1) + \frac{2}{N} \sum_{k=1}^{N} C(k-1) \right]
\overset{-\, (N-1) \cdot C(N-1)}{\longleftrightarrow}](/images/math/0/7/0/070ccdaaebf0c2701672935712a2665b.png)








Für sehr große N gilt:
 beziehungsweise
beziehungsweise 
Mittlere Komplexität:

Verbesserungen des Algorithmus:
- Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks.
- "r" wird immer kleiner → Der rekursive Aufruf lohnt sich nicht mehr. →
Explizites Sortieren einsetzen.
- Das Pivot-Element könnte geschickter gewählt werden: Median.
147.142.207.188 19:31, 23 April 2008 (UTC)