Difference between revisions of "Randomisierte Algorithmen"
| Line 176: | Line 176: | ||
---- | ---- | ||
| − | + | '''Beziehung zu randomisiertem 2-SAT''' | |
"Platz <math>i</math> ": <math>i</math> Variablen haben den richtigen Wert, <math>\left(N-i\right)</math> sind falsch gesetzt | "Platz <math>i</math> ": <math>i</math> Variablen haben den richtigen Wert, <math>\left(N-i\right)</math> sind falsch gesetzt | ||
| Line 182: | Line 182: | ||
<math>S\left(\frac N 2\right)=N^2 - \left(\frac N 2\right)^2 = N^2 - \frac N 4 ^2 = \frac 3 4 N^2 </math> | <math>S\left(\frac N 2\right)=N^2 - \left(\frac N 2\right)^2 = N^2 - \frac N 4 ^2 = \frac 3 4 N^2 </math> | ||
<math>S\left(\frac N 2\right)</math> # Anfangszustand | <math>S\left(\frac N 2\right)</math> # Anfangszustand | ||
| + | ---- | ||
| + | == '''Las Vegas vs. Monte Carlo'''== | ||
| + | |||
| + | * ''Las Vegas - Algorithmen'' | ||
| + | - Ergebnis ist immer korrekt. | ||
| + | - Berechnung ist mit hoher Wahrscheinlichkeit effizient (d.h. Randomisierung macht den ungünstigsten Fall unwahrscheinlich). | ||
| + | |||
| + | * ''Monte Carlo - Algorithmen'' | ||
| + | - Berechnung immer effizient. | ||
| + | - Ergebnis mit hoher Wahrscheinlichkeit korrekt (falls kein effizienter Algorithmus bekannt, der immer die richtige Lösung liefert). | ||
Revision as of 20:17, 10 July 2008
1. Randomisierte Algorithmen
Def.: Algorithmen, die bei Entscheidung oder bei der Wahl der Parameter Zufallszahlen benutzen
Bsp.: Lösen des K-SAT-Problems durch RA
geg.: logischer Ausdruck in K-CNF (n Variablen, m Klauseln, k Variablen pro Klausel)

for i in range (trials): #Anzahl der Versuche
#Bestimme eine Zufallsbelegung des  :
for j in range (steps):
if erfüllt alle Klauseln: return
#wähle zufällig eine Klausel, die nicht erfüllt ist und negiere zufällig eine der Variablen in dieser Klausel
(die Klausel ist jetzt erfüllt)
return None
:
for j in range (steps):
if erfüllt alle Klauseln: return
#wähle zufällig eine Klausel, die nicht erfüllt ist und negiere zufällig eine der Variablen in dieser Klausel
(die Klausel ist jetzt erfüllt)
return None
Eigenschaft: falls 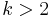 : steps *trials
: steps *trials 
z.B.  steps=3*n, trials=
steps=3*n, trials=
aber: bei  sind im Mittel nur steps=
sind im Mittel nur steps= nötig, trials=
nötig, trials=
-Zufallsbelegung hat  richtige Variablen (im Mittel
richtige Variablen (im Mittel  )
)
Negieren einer Variable ändert t um 1,
u.Z.  mit Wahrscheinlichkeit
mit Wahrscheinlichkeit  ::(für beliebiges k:
::(für beliebiges k:  )
)
 mit Wahrscheinlichkeit ::(für beliebiges k:
mit Wahrscheinlichkeit ::(für beliebiges k:  )
)
-Wieviele Schritte braucht man im Mittel, um zu einer Lösung mit t Richtigen zu kommen?

#Abbruchbedingung der Schleife

Probe:








Das ist das Random Walk Problem
Im ungünstigsten Fall (t=0) werden im Mittel  Schritte benötigt, um durch random walk nach t=n zu gelangen.
Schritte benötigt, um durch random walk nach t=n zu gelangen.
2. RANSAC-ALGORITHMUS (Random Sample Consensus)
Aufgabe: gegeben: Datenpunkte
- gesucht: Modell, das die Datenpunkte erklärt

Messpunkte:
übliche Lösung: Methode der kleinsten Quadrate
 Schulmathematik:
Schulmathematik: 
Lineares Gleichungssystem









- Problem:
 der Datenpunkte sind Outlier
der Datenpunkte sind Outlier
 Einfaches Anpassen des Modells an die Datenpunkte funktioniert nicht
Einfaches Anpassen des Modells an die Datenpunkte funktioniert nicht
- Seien mindestens k Datenpunkte notwendig, um das Programm anpassen zu können
RANSAC-Algorithmus
for l in range (trials):
wähle zufällig k Punkte aus
passe das Modell an die k Punkte an
zähle, wieviele Punkte in der Nähe des Modells liegen (d.h.  muss geschickt gewählt werden)
#Bsp. Geradenfinden:-wähle a,b aus zwei Punkten
-berechne:
muss geschickt gewählt werden)
#Bsp. Geradenfinden:-wähle a,b aus zwei Punkten
-berechne:  -zähle Punkt i als Inlier, falls
-zähle Punkt i als Inlier, falls  return: Modell mit höchster Zahl der Inlier
return: Modell mit höchster Zahl der Inlier
mit k=Anzahl der Datenpunkte und p=Erfolgswahrscheinlichkeit,
=Outlier-Anteil
Erfolgswahrscheinlichkeit: p=99%

Ein Spiel: Wie viel Schritte braucht man im Mittel zum Ziel?
geg.: 5 Plätze, 2 Personen: eine Person rückt vom einem Platz zu dem enderen Platz;
die zweite Person wirft die Münze.
Wenn die Münze auf Kopf landet, rücke nach rechts und wenn die Münze auf Zahl landet, rücke nach links.
<--- Zahl Kopf-->
Kopf: /////
Zahl: ///
- => mit 8 Schritten bis zum Ziel
- im Mittel: bei N Plätzen braucht man N2 Schritte
- all: mit N2 Schritten um N Plätze rücken
- Wie viel Schritte braucht man im Mittel zum Ziel?
#wenn wir uns im Stuhl Nr.1 befinden

#bei 0.Platz
- Lösung:

- speziell:
#wenn man am ungünstigsten Platz startet
Beziehung zu randomisiertem 2-SAT
"Platz":
sind falsch gesetzt

# Anfangszustand
Las Vegas vs. Monte Carlo
* Las Vegas - Algorithmen
- Ergebnis ist immer korrekt.
- Berechnung ist mit hoher Wahrscheinlichkeit effizient (d.h. Randomisierung macht den ungünstigsten Fall unwahrscheinlich).
* Monte Carlo - Algorithmen
- Berechnung immer effizient.
- Ergebnis mit hoher Wahrscheinlichkeit korrekt (falls kein effizienter Algorithmus bekannt, der immer die richtige Lösung liefert).