Difference between revisions of "Sortieren"
(→Alternatives Sortieren kleiner Intervalle) |
(→Beseitigung der Rekursion) |
||
| Line 477: | Line 477: | ||
Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks. Nach jeder Partitionierung wird das größere Teilintervall auf dem Stack abgelegt und das kleinere Teilintervall direkt weiterverarbeitet (hierdurch wird sichergestellt die maximale Größe des Stacks minimiert). | Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks. Nach jeder Partitionierung wird das größere Teilintervall auf dem Stack abgelegt und das kleinere Teilintervall direkt weiterverarbeitet (hierdurch wird sichergestellt die maximale Größe des Stacks minimiert). | ||
| − | def | + | def quicksortNonRecursive(a, l, r): |
stack = [(l,r)] # initialisiere den Stack | stack = [(l,r)] # initialisiere den Stack | ||
while len(stack) > 0: | while len(stack) > 0: | ||
| Line 533: | Line 533: | ||
| C | I | K | O | Q | S | U | | | C | I | K | O | Q | S | U | | ||
+---+---+---+---+---+---+---+ | +---+---+---+---+---+---+---+ | ||
| − | |||
==== Alternatives Sortieren kleiner Intervalle ==== | ==== Alternatives Sortieren kleiner Intervalle ==== | ||
Revision as of 01:30, 27 June 2008
Contents
Laufzeitmesung in Python
Verwendung der timeit-Bibliothek für die Hausaufgabe.
- Importiere das timeit-Modul: import timeit
- Teile den Algorithmus in die Initialisierungen und den Teil, dessen Geschwindigkeit gemessen werden soll. Beide Teile werden in jeweils einen (mehrzeiligen) String eingeschlossen:
+--------+ +----+ setup = """ prog = """ | algo | --> |init| +----+ +----+ | | +----+ |init| |prog| | | +----+ +----+ | | +----+ """ """ | | --> |prog| +--------+ +----+
- aus den beiden Strings wird ein Timeit-Objekt erzeugt: t = timeit.Timer(prog, setup)
- Frage: Wie oft soll die Algorithmik wiederholt werden
- z.B. N = 1000
- Zeit in Sekunden für N Durchläufe: K = t.timeit(N)
- Zeit für 1 Durchlauf: K/N
3.Stunde am 16.04.2008
Sortierverfahren
Motivation
Def: Ein Sortierverfahren ist ein Algorithmus, der dazu dient, eine Liste von Elementen zu sortieren.
- Literatur, siehe Sortierverfahren; Bubblesort 1956, Quicksort 1962. Librarysort 2004
Anwendungen
- Sortierte Daten sind häufig Vorbedingungen für Suchverfahren (Speziell für effiziente Suchalgorithmen mit Komplexität
 )
) - Darstellung von Daten gemäß menschlicher Wahrnehmung
- Aus programmiertechnischer Anwendungssicht hat das Sortierproblem allerdings heute an Relevanz verloren da
- gängige Programmiersprachen heute typunabhängige Algorithmen zur Verfügung stellen. Der Programmierer braucht sich deshalb in den meisten Fällen nicht mehr um die Implementierung von Sortieralgorithmen zu kümmern. In C/C++ sorgen dafür beispielsweise Methoden aus der STL.
- Festplatten / Hauptspeicher heute weniger limitierenden Charakter haben, so dass Standardsortierverfahren meist ausreichen, während komplizierte, speicher-sparende Sortieralgorithmen nur noch selten benötigt werden.
- Die Kenntnis grundlegender Sortieralgorithmen ist trotzdem immer noch nötig: Einerseits kann man vorgefertigte Bausteine nur dann optimal einsetzen, wenn man weiß, was hinter den Kulissen passiert und andererseits verdeutlicht gerade das Sortierproblem wichtige Prinzipien der Algorithmenentwicklung und -analyse in sehr anschaulicher Form.
Vorraussetzungen/ Spielregeln
Mengentheoretische Anforderungen
Definition Totale Ordnung/ Total gordnete Menge:
Eine Totale Ordnung / Total geordnete Menge ist eine binäre Relation
 über einer Menge
über einer Menge  , die transitiv, antisymmetrisch und total ist.
, die transitiv, antisymmetrisch und total ist.
 sei dargestellt als infix Notation
sei dargestellt als infix Notation 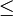 dann, falls M total geordnet, gilt
dann, falls M total geordnet, gilt

(1)  (antisymmetrisch)
(antisymmetrisch)
(2)  (transitiv)
(transitiv)
(3)  (total)
(total)
Bemerkung: aus (3) folgt  (reflexiv)
(reflexiv)
Hab in der Wiki eine gute Seite dazu gefunden Ordnungsrelation
Datenspeicherung
Die Daten liegen typischerweise in Form von Arrays oder verketteten Listen vor. Ja nach Datenstruktur sind andere Sortieralgorithmen am besten geeignet.
- Array
+---+---+---+---+---+---+---+---+---+
|///| | | | | | | |///|
+---+---+---+---+---+---+---+---+---+
\________________ ____________________/
\/
N
Datenelemente können über Indexoperation a[i] gelesen, überschrieben und miteinadner vertauscht werden. Vorteil: Die Zugriffsreihenfolge auf die Datenelemente ist beliebig. Nachteil: Einfügen oder Löschen von Elementen aus dem Array ist relativ aufwändig.
- Vekettete Liste
+---+ +---+ +---+
| | --> | | --> | | --> Ende
+---+ +---+ +---+
Jeder Knoten der Liste enthält ein Datenelement und einen Zeiger auf den nächsten Knoten. Vorteil: Einfügen und Löschen von Elementen ist effizient möglich. Nachteil: effizienter Zugriff nur auf den Nachfolger eines gegebenen Elements, d.h. Zugriffsreihenfolgeist nicht beliebig.
Stabilität
Ein Sortierverfahren heißt stabil falls die relative Reihenfolge gleicher Schlüssel durch die Sortierung nicht verändert wird.
Beispiel: Sortiere eine Liste von Paaren [(3,7), (4,2), (4,1), (2,2), (2,8)], wobei die Reihenfolge nur durch das erste Element (Schlüsselelement) jeden Paares festgelegt wird. Dann erzeugt ein stabiles Sortierverfahren die Ausgabe
[(2,2), (2,8), (3,7), (4,2), (4,1)]
während die Ausgabe
[(2,2), (2,8), (3,7), (4,1), (4,2)]
nicht stabil ist (die Paare (4,1), (4,2) sind vertauscht).
Charakterisierung der Effizienz von Algorithmen
- (a) Komplexität O( 1), O(n), etc. wird in Kapitel Effizienz erklärt.
- (b) Zählen der notwendigen Vergleiche
- (c) Messen der Laufzeit mit 'timeit' (auf identischen Daten)
Rekursive Beziehungen zerlegt die ursprünglichen Probleme in kleinere Probleme und wendet den Algorithmus auf die kleineren Probleme an; daraufhin werden die Teilprobleme zur Lösung des Gesamtproblems verwendet. d.h. Laufzeit (operativer Vergleich) für N Eingaben hängt von der Laufzeit der Eingaben für die Teilprobleme
Aufwand
(i) rekursives/ lineares Durchlaufen der Eingabedaten, Bearbeitung einzelner Elemente
C(N)= C(N-1)+ N ; N>1, C(1)= 1 +---+---+---+---+---+---+---+---+---+
= C(N-2) +(N-1)+ N | 7 | 3 | 2 | 5 | 6 | 8 | 1 | 4 | 2 |
= C(N-3) + (N-2) + (N-1) + N +---+---+---+---+---+---+---+---+---+
= ... ________________________/
= C(1) + 2+...+(N-1) +N /
+---+---+---+---+---+---+---+---+---+
N(N+1) N² | 1 | 3 | 2 | 5 | 6 | 8 | 7 | 4 | 2 |
= ----- ~ -- +---+---+---+---+---+---+---+---+---+
2 2
(ii) rekursives halbieren der Menge der Eingabedaten
C(N)= C(N/2)+1 ; N>1, C(1)=0 Aus Gründen der Einfachheit sei N = 2n C(N)= C(2^n)= C() + 1 = C(
) + n = n =
+---+---+---+---+-|-+---+---+---+---+ | | | | | | | | | | +---+---+---+---+-|-+---+---+---+---+ +---+---+---+---+ | | | | | +---+---+---+---+ +---+---+ +---+ | | | -> | | +---+---+ +---+
(iii) rekursives halbieren, lineare Bearbeitung, jedes Elements
C(N)= 2C(N/2)+ N; N>1, C(1)= 0 Sei N=C(N)= C(
=

==
=... = n
<=> C()= * n
<=> C= N log N
N
Selection Sort
Algorithmus
array = [...] # zu sortierendes Array
for i in range(len(array)-1):
min = i
for j in range(i+1, len(array)):
if a[j]< a[min]:
min = j
a[i], a[min] = a[min], a[i] # Vertausche a[i] mit dem kleinsten rechts befindlichen Element
# Elemente links von a[i] und a[i] selbst befinden sich nun in ihrer endgültigen Position
Beispiel: Sortieren der Liste [S,O,R,T,I,N,G].
erste Iteration der äußeren Schleife, Zustand vor dem Vertauschen:
i=0 min
+---+---+---+---+---+---+---+
| S | O | R | T | I | N | G |
+---+---+---+---+---+---+---+
erste Iteration der äußeren Schleife, Zustand nach dem Vertauschen:
+---|---+---+---+---+---+---+
| G | O | R | T | I | N | S |
+---|---+---+---+---+---+---+
zweite Iteration der äußeren Schleife:
i=1 min
+---|---+---+---+---+---+---+
| G | O | R | T | I | N | S |
+---|---+---+---+---+---+---+
weitere Iterationen:
i=2 min
+---+---|---+---+---+---+---+
| G | I | R | T | O | N | S |
+---+---|---+---+---+---+---+
i=3 min
+---+---+---|---+---+---+---+
| G | I | N | T | O | R | S |
+---+---+---|---+---+---+---+
i=4 min
+---+---+---+---+---+---+---+
| G | I | N | O | T | R | S |
+---+---+---+---+---+---+---+
...
Laufzeit
Da in jeder Iteration der inneren Schleife ein Vergleich a[j]< a[min] durchgeführt wird, ist die Anzahl der Vergleiche ein gutes Maß für den Aufwand des Algorithmus und damit für die Laufzeit. Sei C(N) die Anzahl der notwendigen Vergleiche, um ein Array der größe N zu sortieren. Die Arbeitsweise des Algorithmus kann dann so beschrieben werden: Führe N-1 Vergleiche aus, bringe das kleinste Element an die erste Stelle, und fahre mit dem Sortieren des Rest-Arrays (Größe N-1) rechts des ersten Elements fort. Dafür sind nach Definition noch C(N-1) Vergleiche nötig. Es gilt also:

C(N-1) können wir nach der gleichen Formel einsetzten, und erhalten:

Wir können in dieser Weise weiter fortfahren. Bei C(1) wird das Einsetzen beendet, denn für ein Array der Länge 1 sind keine Vergleiche mehr nötig, also C(1) = 0. Wir erhalten somit




Nach der Gaußschen Summenformel ist dies
 (für große N).
(für große N).
In jedem Durchlauf der äußeren Schleife werden außerdem zwei Elemente ausgetauscht. Es gilt für die Anzahl der Austauschoperationen

Stabilität
Selection Sort ist stabil, wenn die Vergleiche durch a[j] < a[min] erfolgt, weil dann immer das erste Element mit einem gegebenen Schlüssel als erster nach vorn gebracht wird. Bei Vergleichen a[j] <= a[min] wird hingegen das letzte Element zuerst nach vorn gebracht, somit ist Selection Sort dann nicht stabil.
Insertion Sort
- wird in der Übungsgruppe behandelt, siehe auch in der WikiPedia
- Erweiterung: Shell sort
Mergesort
Algorithmus
Zugrunde liegende Idee:
- Zerlege das Problem in zwei möglichst gleich große Teilprobleme ("Teile und herrsche"-Prinzip -- divide and conquer)
- Löse die Teilprobleme rekursiv
- Führen die Teillösungen über Mischen (merging) in richtig sortierter Weise zusammen.
Der Algorithmus besteht somit aus zwei Teilen
Zusammenführen -- merge
a und b sind zwei sortierte Listen, die in eine sortierte Ergebnisliste kombiniert werden.
def merge(a,b):
c = [] # zunächst leere Ergebnisliste
i, j = 0, 0
while i < len(a) and j < len(b):
# wähle des kleinste der noch nicht angefügten Elemente
if a[i] <= b[j]:
c.append(a[i])
i += 1
else:
c.append(b[j])
j += 1
# eine Liste ist jetzt aufgebraucht => der Rest der anderen wird einfach an c angehängt
if i < len(a):
c += a[i:]
else:
c += b[j:]
return c
rekursives Sortieren
def mergeSort(a): # a ist das zu sortierende Array
if len(a) <= 1:
return a # Rekursionsabschluß: leere Arrays und Arrays mit einem Element müssen nicht sortiert werden
else:
left = a[:len(a)/2] # linkes Teilarray
right = a[len(a)/2:] # rechtes Teilarray
leftSorted = mergeSort(left) # rekursives Sortieren der Teilarrays
rightSorted = mergeSort(right) # ...
return merge(leftSorted, rightSorted) # Zusammenführen der Teilarrays
Bei der Sortierung mit Mergesort wird das Array immer in zwei Teile geteilt. → Es entsteht ein Binärbaum der Tiefe  .
.
Beispiel: Sortieren der Liste [S,O,R,T,I,N,G].
Der Algorithmus läuft in der folgenden Skizze zunächst rekursiv von unten nach oben (Zerlegen in Teillisten), danach werden die sortierten Teillisten von oben nach unten zusammengeführt (diese sortierten Teillisten sind in der Skizze dargestellt).
Schritt 0:
S 0 R T I N G S O R T I N G #Arraylänge: N/8 Vergleiche: 0
Schritt 1: \ / \ / \ / /
OS RT IN G OS RT IN / #Arraylänge: N/4 Vergleiche: 3 * 2 = 6
Schritt 2: \ / \ /
ORST GIN ORST GIN #Arraylänge: N/2 Vergleiche: 4 + 3 = 7
\ /
Schritt3: \ /
GINORST GINORST #Arraylänge: N Vergleiche: N = 7
Laufzeit
Man erkennt an der Skizze, dass der Rekursionsbaum für ein Array der Länge N die Tiefe log N hat. Auf jeder Ebene werden weniger als N Vergleiche ausgeführt, so dass insgesamt weniger als N*log N Vergleiche benötigt werden. Dies ist natürlich wesentlich effizienter als die (N-1)*N/2 Vergleiche von Selection Sort. Mathematisch exakt kann man die Anzahl der Vergleiche durch die folgende Rekursionsformel berechnen:

Der Aufwand ergibt sich aus dem Aufwand für die beiden Teilprobleme plus dem Aufwand für N Vergleiche beim Zusammenführen der sortierten Teillisten. Dabei stehen die Zeichen  und
und  für abrunden bzw. aufrunden, weil ein Problem mit ungeradem N nicht in zwei exakt gkeiche Teile geteilt werden kann. Um diese Komplikation zu vermeiden, beschränken wir uns im folgenden auf den Fall
für abrunden bzw. aufrunden, weil ein Problem mit ungeradem N nicht in zwei exakt gkeiche Teile geteilt werden kann. Um diese Komplikation zu vermeiden, beschränken wir uns im folgenden auf den Fall  (mit etwas höherem Aufwand kann man zeigen, dass diese Einschränkung nicht notwendig ist und ide Resultate für alle N gelten). Die vereinfachte Aufwandsformel lautet:
(mit etwas höherem Aufwand kann man zeigen, dass diese Einschränkung nicht notwendig ist und ide Resultate für alle N gelten). Die vereinfachte Aufwandsformel lautet:

Durch Einsetzen der Formel für N/2 erhalten wir:


Die Rekursion endet, weil für ein Array der Größe  keine Vergleiche mehr benötigt werden, also
keine Vergleiche mehr benötigt werden, also  gilt. Mit ist dies aber gerade nach
gilt. Mit ist dies aber gerade nach  Zerlegungen der Fall. Merge Sort benötigt also
Zerlegungen der Fall. Merge Sort benötigt also

Vergleiche.
Weitere Eigenschaften von MergeSort
- Mergesort ist stabil: wegen des Vergleichs a[i] <= b[j] wird die Position gleicher Schlüssel im Algorithmus merge(a,b) nicht verändert -- bei gleichem Schlüssel hat, wie gefordert, das linke Element Vorrang.
- Mergesort ist unempfindlich gegenüber der ursprünglichen Reihenfolge der Eingabedaten. Grund dafür ist
- die vollständige Aufteilung des Ausgangsarrays in Arrays der Länge 1 und
- dass merge(a,b) die Vorsortierung nicht ausnutzt, d.h. die Komplexität von merge(a,b) ist sortierungsunabhängig.
- Diese Eigenschaft kann unerwünscht sein, wenn ein Teil des Arrays oder gar das ganze Array schon sortiert ist. Es wird nämlich in jedem Fall das ganze Array neu sortiert.
- Merge Sort eignet sich für das Sortieren von verketteten Listen, weil die Listenelemente stets von vorn nach hinten durchlaufen werden. In diesem Fall muss merge(a, b) keine neue Liste c für das Ergebnis anlegen, sondern kann einfach die Verkettung der Listenelemente von a und b entsprechend anpassen. In diesem Sinne arbeitet Merge Sort auf verketten Listen "in place", d.h. es wird kein zusätzlicher Speicher benötigt.
- Im Gegensatz dazu benötigt merge(a,b) zusätzlichen Speicher für das Ergebnis c, wenn die Daten in einem Array gegeben sind.
Quicksort
- Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [1] entwickelt. Es gibt viele Implementierungen von Quicksort, vgl. [2].
- Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren.
- Im Gegensatz zu Merge Sort wird das Problem aber nicht immer in zwei fast gleich große Teilprobleme zerlegt. Dadurch vermeidet man, dass zusätzlicher Speicher benötigt wird (Quick Sort arbeitet auch für Arrays "in place"). Allerdings erkauft man sich dies dadurch, dass Quick Sort bei ungünstigen Eingaben (die Bedeutung von "ungünstig" ist je nach Implementation verschieden) nicht effizient arbeitet. Da solche Eingaben jedoch in der Praxis fast nie vorkommen, tut dies der Beliebtheit von Quicksort keinen Abbruch.
Algorithmus
Wie Merge Sort arbeitet Quick Sort rekursiv. Hier werden die Daten allerdings zuerst vorbereitet (in der Funktion partition), und danach erfolgt der rekursive Aufruf:
def quicksort(a, l, r):
"""a ist das zu sortierende Array,
l und r sind die linke und rechte Grenze des zu sortierenden Bereichs"""
if r > l: # Rekursionsabschluss: wenn r <= l, ist der Bereich leer und muss nicht mehr sortiert werden
i = partition(a, l, r) # i ist der Index des sog. Pivot-Elements (s. u.)
quicksort(a, l, i-1) # rekursives Sortieren der beiden Teilarrays
quicksort(a, i+1, r) # ...
Der Schlüssel des Algorithmus ist offensichtlich die Funktion partition. Diese wählt ein Element des Arrays aus (das Pivot-Element) und bringt es an die richtige Stelle (also an den Index i, der von partition zurückgegeben wird). Ausserdem stellt sie sicher, dass alle Elemente in der linken Teilliste (Index < i) kleiner als a[i], und alle Elemente in der rechten Teilliste größer also a[i] sind:
-
![a[i]](/images/math/5/9/5/595711c58954cfc2eb727cba561e3512.png) ist sortiert, d.h. dieses Element ist am endgültigen Platz.
ist sortiert, d.h. dieses Element ist am endgültigen Platz. -
![\forall x \in \left\{ a \left[ l \right] , ... a \left[ i-1 \right] \right\} : x \leq a \left[ i \right]](/images/math/4/8/a/48aae1d8be4cea26da95b8ff77e40cd1.png)
-
![\forall x \in \left\{ a \left[ i+1 \right], ... a \left[ r \right] \right\} : x \geq a \left[ i \right]](/images/math/a/d/c/adcbf0ffe4d766ad8401e1ba9086d5b8.png)
l r
+---+---+---+---+---+---+---+---+---+
Array: | | | | |\\\| | | | |
+---+---+---+---+---+---+---+---+---+
\______ _____/ i \______ _____/
\/ \/
<=a[i] >=a[i] (a[i] ist das Pivot-Element)
Die Position von i richtet sich also offensichtlich danach, wie viele Elemente im Bereich l bis r kleiner bzw. größer als das gewählte Pivot-Element sind. Der Wahl eines guten Pivot-Elements kommt demnach eine große Bedeutung zu (s.u.).
In der einfachsten Version wird partition wie folgt definiert:
def partition(a, l, r):
pivot = a[r] # Pivot-Element. Hier wird willkürlich das letzte Element verwendet.
i = l # i und j sind Laufvariablen
j = r - 1
while True:
while a[i] <= pivot and i < r:
i += 1 # finde von links das erste Element > pivot
while a[j] >= pivot and j > l:
j -= 1 # finde von rechts den ersten Eintrag <= pivot
if i >= j: break # keine weiteren Elemente zum Tauschen => Schleife beenden
a[i], a[j] = a[j], a[i] # a[i] und a[j] sind beide auf der falschen Seite des Pivot => vertausche sie
if a[i] > pivot:
a[i], a[r] = a[r], a[i]
return i
Die folgende Skizze verdeutlicht das Austauschen
p
+---+---+---+---+---+---+---+---+---+
Array: | | | | | | | | |\\\|
+---+---+---+---+---+---+---+---+---+
------> a[i]>p a[j]<p <-----
| |
+---------------+
Diese zwei Elemente werden ausgetauscht.
Dies wird wiederholt, bis sich die Zeiger treffen oder einander überholt haben. Am Schluss wird das Pivot-Element an die richtige Stelle verschoben:
p
+---+---+---+---+---+---+---+---+---+
Array: | | | | |\\\| | | | |
+---+---+---+---+---+---+---+---+---+
i
-----------------> <-----------------
Beispiel: Partitionieren des Arrays [A,S,O,R,T,I,N,G,E,X,A,M,P,L,E] mit Pivot 'E'.
l,i --> <-- j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | S | O | R | T | I | N | G | E | X | A | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i <--------- Vertauschen ---------> j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | S | O | R | T | I | N | G | E | X | A | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i <-------------------> j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | O | R | T | I | N | G | E | X | S | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
j i r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | E | R | T | I | N | G | O | X | S | M | P | L | E | --> Hier wird die
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ Schleife verlassen.
j i <---------------------------------------> r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | E | R | T | I | N | G | O | X | S | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | E | E | T | I | N | G | O | X | S | M | P | L | R | --> Hier wird partition() beendet.
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
Weitere ausführliche Erklärungen der Implementation findet man bei Sedgewick.
Laufzeit
Wir müssen hier den schlechtesten und den typischen Fall unterscheiden. Der schlechteste Fall tritt ein, wenn das Array bereits sortiert ist. Dann ist das Pivot-Element immer bereits am richtigen Platz, so dass partition(a, l, r) stets den Index i = r zurück. Daher wird das Array niemals in zwei etwa gleichgroße Teile zerlegt. Die Anzahl der Vergleiche ergibt sich als


mit (N+1) Vergleichen in partition(). Durch sukzessives Einsetzen erhalten wir:

In diesem Fall ist Quick Sort also nicht schneller als Selection Sort. Wir beschreiben mögliche Verbesserungen unten. Im typischen Fall (wenn nämlich das Array zufällig sortiert ist) sieht die Situation wesentlich besser aus. Bei zufälliger Sortierung wird jeder Index mit gleicher Wahrscheinlichkeit zur Pivot-Position. Wir mitteln deshalb über alle möglichen Positionen:
![C(N) = (N+1) + \frac{1}{N} \sum_{k=1}^{N} \left[ C(k-1) + C(N-k) \right]](/images/math/c/c/b/ccb8bc97d5005caa14d9fb9ab5861d07.png) für
für 
wobei  über alle möglichen Teilungspunkte läuft. Die Summe (der mittlere Aufwand über alle möglichen Zerlegungen) kann vereinfacht werden zu
über alle möglichen Teilungspunkte läuft. Die Summe (der mittlere Aufwand über alle möglichen Zerlegungen) kann vereinfacht werden zu
![\frac{1}{N} \sum_{k=1}^{N} \left[ C(k-1) + C(N-k) \right] = 2 \frac{1}{N} \sum_{k=1}^{N} C(k-1)](/images/math/d/4/4/d441dcff585e15d5779fc23fdca6d344.png)
Die Auflösung der Formel ist etwas trickreich. Wir multiplizieren zunächst beide Seiten mit N:
![N \cdot C(N) = N \left[ (N+1) + \frac{2}{N} \sum_{k=1}^{N} C(k-1) \right] = N (N+1) + 2\; \sum_{k=1}^{N} C(k-1)](/images/math/2/b/1/2b12a29d5da68b862895b216f80ed4a8.png)
Durch die Substitution  erhalten wir die entsprechende Formel für N-1:
erhalten wir die entsprechende Formel für N-1:

Wir subtrahieren die Formel für N-1 von der Formel für N und eliminieren dadurch die Summe (nur der letzte Summend der ersten Summe bleibt übrig):

Durch Vereinfachen erhalten wir die rekurrente Beziehung

Wir teilen jetzt beide Seiten durch  Sukzessives Einsetzten der Formel für C(N-1), C(N-2) etc. bis liefert
Sukzessives Einsetzten der Formel für C(N-1), C(N-2) etc. bis liefert

Für hinreichend große N kann die Summe sehr genau durch ein Integral approximiert werden. Der konstanten Term kann vernachlässigt werden:

Somit benötigt Quick Sort im typischen Fall

Vergleiche. Quick Sort ist demnach etwa genauso schnell wie Merge Sort (in der Praxis sogar etwas schneller, da die innere Schleife von Quick Sort etwas einfacher ist).
Verbesserungen des Quicksort-Algorithmus
Beseitigung der Rekursion
Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks. Nach jeder Partitionierung wird das größere Teilintervall auf dem Stack abgelegt und das kleinere Teilintervall direkt weiterverarbeitet (hierdurch wird sichergestellt die maximale Größe des Stacks minimiert).
def quicksortNonRecursive(a, l, r):
stack = [(l,r)] # initialisiere den Stack
while len(stack) > 0:
if r > l:
i = partition(a, l, r)
if (i-l) > (r-i):
stack.append((l,i-1))
l = i+1
else:
stack.append((i+1, r))
r = i-1
else:
l, r = stack.pop()
Die ist die Methoder der Endrekursionsbeseitigung, die wir im Kapitel Iteration versus Rekursion ausführlich behandeln. Die folgende Skizze verdeutlicht die Verwendung des Stacks.
+---+---+---+---+---+---+---+
| Q | U | I | C | K | S | O |
+---+---+---+---+---+---+---+
+---+---+---+===+---+---+---+
| K | C | I |=O=| Q | S | U |
+---+---+---+===+---+---+---+
\_________/
push
+---+===+---+
| C |=I=| K |
+---+===+---+
\_/
push
+===+
|=C=|
+===+
+===+
|=K=|
+===+
+---+---+===+
| Q | S |=U=|
+---+---+===+
+---+===+
| Q |=S=|
+---+===+
+===+
|=Q=|
+===+
+---+---+---+---+---+---+---+
| C | I | K | O | Q | S | U |
+---+---+---+---+---+---+---+
Alternatives Sortieren kleiner Intervalle
Für kleine Arrays (bis zu einer gegebenen Größe K) ist das "Teile und herrsche"-Prinzip nicht die effizienteste Herangehensweise. Insbesondere kann man ein Array mit maximal 3 Elementen direkt sortieren:
def sortThree(a, l, r):
if r > l and a[l+1] < a[l]: # Stelle sicher, dass a[l] und a[l+1] relativ zueinander sortiert sind.
a[l], a[l+1] = a[l+1], a[l]
if r == l + 2 and a[r] < a[l]: # Stelle sicher, dass a[l] und a[r] relativ zueinander sortiert sind.
a[l], a[r] = a[r], a[l] # Danach ist a[l] auf jeden Fall das kleinste Element.
if r == l + 2 and a[r] < a[r-1]:
a[r], a[r-1] = a[r-1], a[r] # Stelle sicher, dass a[r-1] und a[r] relativ zueinander sortiert sind.
# Jetzt ist a[r] auf jeden Fall das größte Element und das Arra damit sortiert.
In die Funktion quickSort() wird jetzt ein Aufruf dieser Funktion eingefügt:
if r-l >= 3:
# wie bisher
elif r-l > 0:
sortThree(a, l, r)
Günstige Selektion des Pivot-Elements
- Das Pivot-Element könnte geschickter gewählt werden. Methode: Median von drei Elementen: Bestimme den Median der ersten, mittleren und letzten Elements eines Arrays und verwende der Median als Pivot-Element
- Diese Methode minimiert die Häufigkeit des Auftetens des ungünstigsten Falles.
147.142.207.188 19:31, 23 April 2008 (UTC)