Difference between revisions of "Sortieren"
(→Charakterisierung der Effizienz von Algorithmen) |
|||
| Line 80: | Line 80: | ||
<br/> | <br/> | ||
| − | === Mergesort === | + | |
| − | ==== Algorithmus ==== | + | === 3.3 Mergesort === |
| − | # <tt>c ← merge(a,b)</tt> ( | + | ==== a) Algorithmus ==== |
| − | # '''rekursiver Mergesort''' | + | |
| + | # Zugrunde liegende Idee: | ||
| + | * "Teile und herrsche"-Prinzip (divide and conquer) zur Zerlegung in Teilprobleme | ||
| + | * Zusammenführen der Lösungen über Mischen (merging) | ||
| + | ** two-way | ||
| + | ** multi-way | ||
| + | ==== a.1) Algorithmus <tt>c ← merge(a,b)</tt> ==== | ||
| + | |||
| + | c = merge(a,b) ← { # Kombination zweier sortierter Listen a_i und b_j | ||
| + | # zu einer sortierten Ausgabeliste c_k | ||
| + | a[M+1] ← maxint | ||
| + | b[N+1] ← maxint | ||
| + | |||
| + | for k ← 1 to M+N | ||
| + | if a[i] < b[j] | ||
| + | c[k] > a[i] | ||
| + | i ← i+1 | ||
| + | else | ||
| + | c[k] ← b[j] | ||
| + | j ← j+1 | ||
| + | } | ||
| + | |||
| + | |||
| + | ==== a.2)'''rekursiver Mergesort''' ==== | ||
mergesort(m) ← { #m ist ein Array | mergesort(m) ← { #m ist ein Array | ||
| − | if |m| > 1 | + | if |m| > 1 #True, wenn m mehr als 1 Element hat. |
a ← mergesort(m[1:<|m|/2]) | a ← mergesort(m[1:<|m|/2]) | ||
| − | b ← mergesort(m[|m|/2 | + | b ← mergesort(m[(|m|/2)+1:|m|]) |
c ← merge(a,b) | c ← merge(a,b) | ||
return(c) | return(c) | ||
| Line 95: | Line 118: | ||
} | } | ||
| − | + | (Eine In-place-Implementierung siehe bei Sedgewick.) | |
| − | entsteht ein Binärbaum der Tiefe <math>lgN</math>. | + | Bei der Sortierung mit Mergesort wird das Array immer in zwei Teile geteilt. → Es entsteht ein Binärbaum der Tiefe <math>lgN</math>. |
| − | [ | + | Gegebene unsortierte Liste: [S,O,R,T,I,N,G] |
| + | Die Teile werden bei jedem Schritt paarweise gemischt. | ||
| − | + | Schritt 0: | |
| + | S 0 R T I N G S O R T I N G #Arraylänge: N/8 | ||
| + | Schritt 1: \ / \ / \ / / | ||
| + | OS RT IN G OS RT IN / #Arraylänge: N/4 Vergleiche: N/4 * 4 | ||
| + | Schritt 2: \ / \ / | ||
| + | ORST GIN ORST GIN #Arraylänge: N/2 Vergleiche: N/2 * 2 | ||
| + | \ / | ||
| + | Schritt3: \ / | ||
| + | GINORST GINORST #Arraylänge: N Vergleiche: N | ||
| − | |||
| − | |||
| − | |||
| − | + | Zeitkomplexität: <math>C(N) - N \cdot lgN</math> | |
| − | |||
| − | |||
| − | ==== | + | ==== b) Komplexität ==== |
| − | + | Komplexität: <math>C(N) = 2 \cdot C \left( \frac{N}{2} \right) + N = N \cdot log_2 N </math> (für N = <math>2^n</math> ) | |
| − | < | + | Erklärungen zur Formel: |
| − | + | * <math> C \left(\frac{N}{2}\right) </math>: "für jede Hälfte des Arrays" | |
| − | + | * <math> +N </math>: für das Zusammenführen | |
| − | * | + | * N Vergleiche pro Ebene |
| + | * Insgesamt gibt es <math> log_2 N </math> Ebenen. | ||
| − | + | ==== c) Weitere Eigenschaften von MergeSort ==== | |
| − | 1. | + | * Mergesort ist '''stabil''', weil die Position gleicher Schlüssel im Algorithmus <tt>merge(a,b)</tt> nicht verändert wird - wegen <tt>„<”</tt> hat das linke Element Vorrang. |
| + | * Mergesort ist '''unempfindlich gegenüber der ursprünglichen Reihenfolge der Eingabedaten'''. Grund dafür ist die vollständige Aufteilung des Ausgangsarrays in Arrays der Länge 1. | ||
* Diese Eigenschaft ist dann unerwünscht, wenn ein Teil des Arrays oder gar das | * Diese Eigenschaft ist dann unerwünscht, wenn ein Teil des Arrays oder gar das | ||
Revision as of 23:53, 12 May 2008
Contents
Laufzeitmesung in Python
Verwendung der timeit-Bibliothek für die Hausaufgabe.
- Importiere das timeit-Modul: import timeit
- Teile den Algorithmus in die Initialisierungen und den Teil, dessen Geschwindigkeit gemessen werden soll. Beide Teile werden in jeweils einen (mehrzeiligen) String eingeschlossen:
+--------+ +----+ setup = """ prog = """ | algo | --> |init| +----+ +----+ | | +----+ |init| |prog| | | +----+ +----+ | | +----+ """ """ | | --> |prog| +--------+ +----+
- aus den beiden Strings wird ein Timeit-Objekt erzeugt: t = timeit.Timer(prog, setup)
- Frage: Wie oft soll die Algorithmik wiederholt werden
- z.B. N = 1000
- Zeit in Sekunden für N Durchläufe: K = t.timeit(N)
- Zeit für 1 Durchlauf: K/N
3.Stunde am 16.04.2008
Sortierverfahren
Motivation
Def: Ein Sortierverfahren ist ein Algorithmus, der dazu dient, eine Liste von Elementen zu sortieren.
Anwendungen
- Sortierte Daten sind häufig Vorbedingungen für Suchverfahren (Speziell für Algorithmen mit Log(N) Komplexität)
- Darstellung von Daten gemäß menschlicher Wahrnehmung
- Bemerkung: aus programmiertechnischer Anwenwendungssicht hat das Sortierproblem an Relevanz verloren da
- Festplatten / Hauptspeicher heute weniger limitierenden Charakter haben, so dass komplizierte, speicher-sparende Sortieralgorithmen nur noch in wenigen Fällen benötigt werden.
- gängige Programmiersprachen heute typenabhängige Algorithmen zur Verfügung stellen. Der Programmierer braucht deshalb sich in den meisten Fällen nicht mehr um die Implementierung von Sortieralgorithmen kümmern. In C/C++ sorgen dafür beispielsweise Methoden aus der STL
Vorraussetzungen/ Spielregeln
Mengentheoretische Anforderungen
- Definition Totale Ordnung/ Total gordnete Menge
Eine Totale Ordnung / Total geordnete Menge ist eine binäre Relation
 über einer Menge
über einer Menge  , die transitiv, antisymmetrisch und total ist.
, die transitiv, antisymmetrisch und total ist.
 sei dargestellt als infix Notation
sei dargestellt als infix Notation 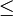 dann, falls M total geordnet, gilt
dann, falls M total geordnet, gilt

(1)  (antisymmetrisch)
(antisymmetrisch)
(2)  (transitiv)
(transitiv)
(3)  (total)
(total)
Bemerkung: aus (3) folgt  (reflexiv)
(reflexiv)
Hab in der Wiki eine gute Seite dazu gefunden Ordnungsrelation
Datenspeicherung
a) Array (Grafik folgt noch)
b) Vekettete Liste
Nachteil Adressierung bsp: 10 > 9
Charakterisierung der Effizienz von Algorithmen
- (a) Komplexität O(1), O(n), etc. wird in Kapitel Effizienz erklärt.
- (b) Zählen der notwendigen Vergleiche
- (c) Messen der Laufzeit mit 'timeit' (auf identischen Daten)
Rekursive Zerlegung zerlegt Ursprüngliche Probleme in kleinere Probleme und wendet sie auf die kleineren Probleme an; daraufhin werden die Teilprobleme zur Lösung des Gesamtproblems verwendet. Aufwand für N Eingaben, hängt ab vom Aufwand der Eingaben geringeren Umfangs ab. (Teilprobleme)
----
4. Stunde, am 17.04.2008
(Fortsetzung der Stunde vom 16.04.2008)
3.3 Mergesort
a) Algorithmus
- Zugrunde liegende Idee:
- "Teile und herrsche"-Prinzip (divide and conquer) zur Zerlegung in Teilprobleme
- Zusammenführen der Lösungen über Mischen (merging)
- two-way
- multi-way
a.1) Algorithmus c ← merge(a,b)
c = merge(a,b) ← { # Kombination zweier sortierter Listen a_i und b_j
# zu einer sortierten Ausgabeliste c_k
a[M+1] ← maxint
b[N+1] ← maxint
for k ← 1 to M+N
if a[i] < b[j]
c[k] > a[i]
i ← i+1
else
c[k] ← b[j]
j ← j+1
}
a.2)rekursiver Mergesort
mergesort(m) ← { #m ist ein Array
if |m| > 1 #True, wenn m mehr als 1 Element hat.
a ← mergesort(m[1:<|m|/2])
b ← mergesort(m[(|m|/2)+1:|m|])
c ← merge(a,b)
return(c)
else
return(m)
}
(Eine In-place-Implementierung siehe bei Sedgewick.)
Bei der Sortierung mit Mergesort wird das Array immer in zwei Teile geteilt. → Es entsteht ein Binärbaum der Tiefe  .
.
Gegebene unsortierte Liste: [S,O,R,T,I,N,G] Die Teile werden bei jedem Schritt paarweise gemischt.
Schritt 0:
S 0 R T I N G S O R T I N G #Arraylänge: N/8
Schritt 1: \ / \ / \ / /
OS RT IN G OS RT IN / #Arraylänge: N/4 Vergleiche: N/4 * 4
Schritt 2: \ / \ /
ORST GIN ORST GIN #Arraylänge: N/2 Vergleiche: N/2 * 2
\ /
Schritt3: \ /
GINORST GINORST #Arraylänge: N Vergleiche: N
Zeitkomplexität: 
b) Komplexität
Komplexität:  (für N =
(für N = 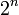 )
)
Erklärungen zur Formel:
-
 : "für jede Hälfte des Arrays"
: "für jede Hälfte des Arrays" -
 : für das Zusammenführen
: für das Zusammenführen - N Vergleiche pro Ebene
- Insgesamt gibt es
 Ebenen.
Ebenen.
c) Weitere Eigenschaften von MergeSort
- Mergesort ist stabil, weil die Position gleicher Schlüssel im Algorithmus merge(a,b) nicht verändert wird - wegen „<” hat das linke Element Vorrang.
- Mergesort ist unempfindlich gegenüber der ursprünglichen Reihenfolge der Eingabedaten. Grund dafür ist die vollständige Aufteilung des Ausgangsarrays in Arrays der Länge 1.
- Diese Eigenschaft ist dann unerwünscht, wenn ein Teil des Arrays oder gar das
ganze Array schon sortiert ist. Es wird nämlich in jedem Fall das ganze Array neu
sortiert.
Quicksort
- Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [1] entwickelt. Es gibt viele Implementierungen von Quicksort, siehe vgl. [2].
- Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren.
grundlegender Algorithmus
quicksort(l,r) ← { #l: linke Grenze, r: rechte Grenze des Arrays
#Das Array läuft also von l bis r (a[l:r])
if r > l
i ← partition(l,r) #i ist das Pivot-Element
quicksort(l,i-1) #quicksort auf beide Hälfte des Arrays anwenden
quicksort(i+1,r)
}
Dieser Algorithmus wird rekursiv für zwei Teilstücke links und rechts des Pivot-Elements aufgerufen. Das Pivot-Element ist nach diesem Schritt an der richtigen Position (d.h. links von der Stelle i stehen nur kleinere, rechts von i nur größere Elemente als das Pivot-Element). Die Methode partition sorgt dafür, dass diese Bedingung erfüllt ist.
Algorithmus für partition
Aufgabe: Ordne a so um, dass nach der Wahl von i (Pivot-Element)
gilt:
-
![a[i]](/images/math/5/9/5/595711c58954cfc2eb727cba561e3512.png) ist sortiert, d.h. dieses Element ist am endgültigen Platz.
ist sortiert, d.h. dieses Element ist am endgültigen Platz. -
![\forall x \in \left\{ a \left[ l \right] , ... a \left[ i-1 \right]
\right\} : x \leq a \left[ i \right]](/images/math/4/8/a/48aae1d8be4cea26da95b8ff77e40cd1.png)
-
![\forall x \in \left\{ a \left[ i+1 \right], ... a \left[ r \right]
\right\} : x \geq a \left[ i \right]](/images/math/a/d/c/adcbf0ffe4d766ad8401e1ba9086d5b8.png)
Abbildung fehlt noch a[i] heißt Pivot-Element (p)
i ← partition(l,r) ← {
p ← a[r] #p: Pivot-Element. Hier wird willkürlich das rechteste Element
# als Pivot-Element genommen.
i ← l-1 #i und j sind Laufvariablen
j ← r
repeat
repeat
i ← i+1 #Finde von links den ersten Eintrag >= p
until a[i] >= p
repeat
j ← j+1 #Finde von rechts den ersten Eintrag <= p
until a[j] <= p
swap(a[i], a[j])
until j <= i #Nachteile: p steht noch rechts
swap(a[i], a[j]) #Letzter Austausch zwischen i und j muss
#zurückgenommen werden
swap(a[i], a[r])
return(i)
}
Bemerkungen zur gegebenen Implementierung:
- Sie benötigt ein Dummy-Minimalelement.
- Dieses Element ist durch zusätzliche if-Abfrage vermeidbar, aber die
if-Abfrage erhöht die Komplexität des Algorithmus (schlechte Performanz).
- Sie ist ineffizient für (weitgehend) sortierte Arrays, da sich folgende
Aufteilung für die Partitionen ergibt:
- Erste Partition: [l,i-1], zweite Partition: [i+1,r]
- Die erste Partition umfasst N-1 Elemente
- Die zweite Partition ist leer (bzw. sie existiert nicht), weil das Pivot-Element p = r gewählt wurde. Das Array wird also elementweise abgearbeitet.
- → N einzelne Aufrufe ⇒ Zeitkomplexität:
 (siehe Berechnung vom 16.04.2008)
(siehe Berechnung vom 16.04.2008) - Für identische Schlüssel sollten beide Laufvariablen stehen bleiben.
- Bei der gegebenen Implementierung tauscht auch gleiche Elemente aus.
- Für identische Schlüssel können die Abbruchbedingungen verbessert werden (siehe
Sedgewick).
Komplexität
![C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k)
\right]](/images/math/8/5/0/8501ba6065bba57762180b2267ce066a.png) für
für 
Anmerkungen zur Formel:
-
 : Vergleiche für jeden Aufruf
: Vergleiche für jeden Aufruf -
 : Teilungspunkt
: Teilungspunkt
![\frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) \right] = 2 \frac{1}{N}
\sum_{k=1}^{N} C(k-1)](/images/math/c/3/0/c3035051266f59bfb6fd2d2d0b8c7b94.png)
![C(N) = (N+1) + \frac{1}{N} \sum_{m=1}^{N} \left[ C(k-1) + C(N-k) \right]
\overset{\cdot N}{\longleftrightarrow}](/images/math/b/b/2/bb27677b46385665077a41bf199494ca.png)
![N \cdot C(N) = N \left[ (N+1) + \frac{2}{N} \sum_{k=1}^{N} C(k-1) \right]
\overset{-\, (N-1) \cdot C(N-1)}{\longleftrightarrow}](/images/math/0/7/0/070ccdaaebf0c2701672935712a2665b.png)








Für sehr große N gilt:
 beziehungsweise
beziehungsweise 
Mittlere Komplexität:

Verbesserungen des Algorithmus
- Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks.
- "r" wird immer kleiner → Der rekursive Aufruf lohnt sich nicht mehr. → Explizites Sortieren einsetzen.
- Das Pivot-Element könnte geschickter gewählt werden: Median.
147.142.207.188 19:31, 23 April 2008 (UTC)