Difference between revisions of "Sortieren"
(→1.Motivation) |
m (→a.1) Algorithmus c ← merge(a,b): Code als ein block) |
||
| Line 252: | Line 252: | ||
c[k] ← b[j] | c[k] ← b[j] | ||
j ← j+1 | j ← j+1 | ||
| − | |||
} | } | ||
Revision as of 15:16, 20 June 2008
Contents
Laufzeitmesung in Python
Verwendung der timeit-Bibliothek für die Hausaufgabe.
- Importiere das timeit-Modul: import timeit
- Teile den Algorithmus in die Initialisierungen und den Teil, dessen Geschwindigkeit gemessen werden soll. Beide Teile werden in jeweils einen (mehrzeiligen) String eingeschlossen:
+--------+ +----+ setup = """ prog = """ | algo | --> |init| +----+ +----+ | | +----+ |init| |prog| | | +----+ +----+ | | +----+ """ """ | | --> |prog| +--------+ +----+
- aus den beiden Strings wird ein Timeit-Objekt erzeugt: t = timeit.Timer(prog, setup)
- Frage: Wie oft soll die Algorithmik wiederholt werden
- z.B. N = 1000
- Zeit in Sekunden für N Durchläufe: K = t.timeit(N)
- Zeit für 1 Durchlauf: K/N
3.Stunde am 16.04.2008
Sortierverfahren
1.Motivation
Def: Ein Sortierverfahren ist ein Algorithmus, der dazu dient, eine Liste von Elementen zu sortieren.
- Literatur, ride Sortierverfahren; Bubblesort 1956, Quicksort 1962. Librarysort 2004
Anwendungen
- Sortierte Daten sind häufig Vorbedingungen für Suchverfahren (Speziell für Algorithmen mit Log(N) Komplexität)
- Darstellung von Daten gemäß menschlicher Wahrnehmung
- Bemerkung: aus programmiertechnischer Anwendungssicht hat das Sortierproblem an Relevanz verloren da
- Festplatten / Hauptspeicher heute weniger limitierenden Charakter haben, so dass komplizierte, speicher-sparende Sortieralgorithmen nur noch in wenigen Fällen benötigt werden.
- gängige Programmiersprachen heute typunabhängige Algorithmen zur Verfügung stellen. Der Programmierer braucht sich deshalb in den meisten Fällen nicht mehr um die Implementierung von Sortieralgorithmen zu kümmern. In C/C++ sorgen dafür beispielsweise Methoden aus der STL
2. Vorraussetzungen/ Spielregeln
- Mengentheoretische Anforderungen a Elemente - Datenspeicherung Array / Liste - Charakterisierung von Algorithmen -- Komplexität (Speicher/ Laufzeit) -- Stabilität -- allg. Eigenschaften (Rekursivität/ Vergleich/ Methoden)
2.1 Mengentheoretische Anforderungen
Definition Totale Ordnung/ Total gordnete Menge:
Eine Totale Ordnung / Total geordnete Menge ist eine binäre Relation
 über einer Menge
über einer Menge  , die transitiv, antisymmetrisch und total ist.
, die transitiv, antisymmetrisch und total ist.
 sei dargestellt als infix Notation
sei dargestellt als infix Notation 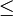 dann, falls M total geordnet, gilt
dann, falls M total geordnet, gilt

(1)  (antisymmetrisch)
(antisymmetrisch)
(2)  (transitiv)
(transitiv)
(3)  (total)
(total)
Bemerkung: aus (3) folgt  (reflexiv)
(reflexiv)
Hab in der Wiki eine gute Seite dazu gefunden Ordnungsrelation
2.2 Datenspeicherung
a) Array ---
+---+---+---+---+---+---+---+---+---+
|///| | | | | | | |///| Einfügen oder Löschen
+---+---+---+---+---+---+---+---+---+
\________________ ____________________/
\/
N
b) Vekettete Liste
+---+ +---+ +---+
| |-> | |-> | |-> Z
+---+ +---+ +---+
Datenelement zeigt auf das Nächste Nachteil: lineares array (Adressierung bsp: 10 > 9)
Charakterisierung der Effizienz von Algorithmen
- (a) Komplexität O( 1), O(n), etc. wird in Kapitel Effizienz erklärt.
- (b) Zählen der notwendigen Vergleiche
- (c) Messen der Laufzeit mit 'timeit' (auf identischen Daten)
Rekursive Beziehungen zerlegt die ursprünglichen Probleme in kleinere Probleme und wendet den Algorithmus auf die kleineren Probleme an; daraufhin werden die Teilprobleme zur Lösung des Gesamtproblems verwendet. d.h. Laufzeit (operativer Vergleich) für N Eingaben hängt von der Laufzeit der Eingaben für die Teilprobleme
Aufwand
(i) rekursives/ lineares Durchlaufen der Eingabedaten, Bearbeitung einzelner Elemente
C(N)= C(N-1)+ N ; N>1, C(1)= 1 +---+---+---+---+---+---+---+---+---+
= C(N-2) +(N-1)+ N | 7 | 3 | 2 | 5 | 6 | 8 | 1 | 4 | 2 |
= C(N-3) + (N-2) + (N-1) + N +---+---+---+---+---+---+---+---+---+
= ... ________________________/
= C(1) + 2+...+(N-1) +N /
+---+---+---+---+---+---+---+---+---+
N(N+1) N² | 1 | 3 | 2 | 5 | 6 | 8 | 7 | 4 | 2 |
= ----- ~ -- +---+---+---+---+---+---+---+---+---+
2 2
(ii) rekursives halbieren der Menge der Eingabedaten
C(N)= C(N/2)+1 ; N>1, C(1)=0 Aus Gründen der Einfachheit sei N = 2n C(N)= C(2^n)= C() + 1 = C(
) + n = n =
+---+---+---+---+-|-+---+---+---+---+ | | | | | | | | | | +---+---+---+---+-|-+---+---+---+---+ +---+---+---+---+ | | | | | +---+---+---+---+ +---+---+ +---+ | | | -> | | +---+---+ +---+
(iii) rekursives halbieren, lineare Bearbeitung, jedes Elements
C(N)= 2C(N/2)+ N; N>1, C(1)= 0 Sei N=C(N)= C(
=

==
=... = n
<=> C()= * n
<=> C= N log N
N
(b) Stabilität
Definition: stabiles Sortierverfahren
Ein Sortierverfahren heißt stabil falls die relative Reihenfolge gleicher Schlüssel M der Ausgangsdaten beibehält.
Beispiel:
(3,7) / (1,8)
(4,2) /stabil (2,2)
(4,1) / (3,7)
(4,2)
(2,2) \ ....
(1,8) \ nicht stabil (4,1)
\ (4,2)
3. Sortierverfahren
insertion sort N² selection sort N² Bubblesort N log N Quicksort N log N
3.1 Selection Sort
a) Algorithmus
for i= 1 to N-1
min <- 1;
for j= i+1 to N
if a[j]< a min
min <- j
swap(a[min], a[i]) //Elemente links von i befinden sich an endgültiger Position
+---+---+---+---+---+---+---+ | S | O | R | T | I | N | G | +---+---+---+---+---+---+---+ i +---|---+---+---+---+---+---+ | G | O | R | T | I | N | S | +---|---+---+---+---+---+---+ i +---+---|---+---+---+---+---+ | G | I | R | T | O | N | S | +---+---|---+---+---+---+---+ i +---+---+---|---+---+---+---+ | G | I | N | T | O | R | S | +---+---+---|---+---+---+---+ i +---+---+---+---+---+---+---+ | G | I | N | O | T | R | S | +---+---+---+---+---+---+---+
..
b) Komplexität
- Anzahl Vergleiche
C(N)= C(N-1)+ (N-1)
= C(N-2)+ (N-2)+ (N-1)
...
= 1+2 + ...+ (N-2)+ (N-1)
= 
 - Anzahl Austauschoperationen
C(N)= C(N-1)+1; C(1)= 0; n>1
= N-1
- Anzahl Austauschoperationen
C(N)= C(N-1)+1; C(1)= 0; n>1
= N-1
c) Stabilität
Im Allg. zur Prüfung a[j]<a[min] ist Selection Sort stabil falls
3.2 Insertion Sort
- Teil der Übung - Erweiteung: Shell sort
4. Stunde, am 17.04.2008
(Fortsetzung der Stunde vom 16.04.2008)
Mergesort
a) Algorithmus
Zugrunde liegende Idee:
- "Teile und herrsche"-Prinzip (divide and conquer) zur Zerlegung des Problems in Teilprobleme.
- Zusammenführen der Lösungen über Mischen (merging): "two-way" oder "multi-way".
a.1) Algorithmus c ← merge(a,b)
c = merge(a,b) ← { # Kombination zweier sortierter Listen a[i] und b[j]
# zu einer sortierten Ausgabeliste c[k]
a[M+1] ← maxint
b[N+1] ← maxint
for k ← 1 to M+N
if a[i] < b[j]
c[k] > a[i]
i ← i+1
else
c[k] ← b[j]
j ← j+1
}
a.2) rekursiver Mergesort
mergesort(m) ← { #m ist ein Array
if |m| > 1 #True, wenn m mehr als 1 Element hat.
a ← mergesort(m[1:<|m|/2])
b ← mergesort(m[(|m|/2)+1:|m|])
c ← merge(a,b)
return(c)
else
return(m)
}
(Eine In-place-Implementierung siehe bei Sedgewick.)
Bei der Sortierung mit Mergesort wird das Array immer in zwei Teile geteilt. → Es entsteht ein Binärbaum der Tiefe  .
.
Gegebene unsortierte Liste: [S,O,R,T,I,N,G] Die Teile werden bei jedem Schritt paarweise gemischt.
Schritt 0:
S 0 R T I N G S O R T I N G #Arraylänge: N/8
Schritt 1: \ / \ / \ / /
OS RT IN G OS RT IN / #Arraylänge: N/4 Vergleiche: N/4 * 4
Schritt 2: \ / \ /
ORST GIN ORST GIN #Arraylänge: N/2 Vergleiche: N/2 * 2
\ /
Schritt3: \ /
GINORST GINORST #Arraylänge: N Vergleiche: N
Zeitkomplexität: 
b) Komplexität
Komplexität:  (für N = )
(für N = )
Erklärungen zur Formel:
-
 : "für jede Hälfte des Arrays"
: "für jede Hälfte des Arrays" -
 : für das Zusammenführen
: für das Zusammenführen - N Vergleiche pro Ebene
- Insgesamt gibt es Ebenen.
c) Weitere Eigenschaften von MergeSort
- Mergesort ist stabil, weil die Position gleicher Schlüssel im Algorithmus merge(a,b) nicht verändert wird - wegen „<” hat das linke Element Vorrang.
- Mergesort ist unempfindlich gegenüber der ursprünglichen Reihenfolge der Eingabedaten. Grund dafür ist
- die vollständige Aufteilung des Ausgangsarrays in Arrays der Länge 1 und
- dass merge(a,b) die Vorsortierung nicht ausnutzt, d.h. die Komplexität von merge(a,b) ist sortierungsunabhängig.
- Diese Eigenschaft ist dann unerwünscht, wenn ein Teil des Arrays oder gar das ganze Array schon sortiert ist. Es wird nämlich in jedem Fall das ganze Array neu sortiert.
Quicksort
- Quicksort wurde in den 60er Jahren von Charles Antony Richard Hoare [1] entwickelt. Es gibt viele Implementierungen von Quicksort, vgl. [2].
- Dieser Algorithmus gehört zu den "Teile und herrsche"-Algorithmen (divide-and-conquer) und ist der Standardalgorithmus für Sortieren.
a) Algorithmus für quicksort
quicksort(l,r) ← { #l: linke Grenze, r: rechte Grenze des Arrays
#Das Array läuft also von l bis r (a[l:r])
if r > l
i ← partition(l,r) #i ist das Pivot-Element
quicksort(l,i-1) #quicksort auf beide Hälfte des Arrays anwenden
quicksort(i+1,r)
}
Dieser Algorithmus wird rekursiv für zwei Teilstücke links und rechts des Pivot-Elements aufgerufen. Das Pivot-Element ist nach diesem Schritt an der richtigen Position (d.h. links von der Stelle i stehen nur kleinere, rechts von i nur größere Elemente als das Pivot-Element). Die Methode partition sorgt dafür, dass diese Bedingung erfüllt ist.
b) Algorithmus für partition
Aufgabe: Ordne a so um, dass nach der Wahl von i (Pivot-Element) gilt:
-
![a[i]](/images/math/5/9/5/595711c58954cfc2eb727cba561e3512.png) ist sortiert, d.h. dieses Element ist am endgültigen Platz.
ist sortiert, d.h. dieses Element ist am endgültigen Platz. -
![\forall x \in \left\{ a \left[ l \right] , ... a \left[ i-1 \right] \right\} : x \leq a \left[ i \right]](/images/math/4/8/a/48aae1d8be4cea26da95b8ff77e40cd1.png)
-
![\forall x \in \left\{ a \left[ i+1 \right], ... a \left[ r \right] \right\} : x \geq a \left[ i \right]](/images/math/a/d/c/adcbf0ffe4d766ad8401e1ba9086d5b8.png)
- a[i] heißt Pivot-Element (p)
l r
+---+---+---+---+---+---+---+---+---+
Array: | | | | |\\\| | | | |
+---+---+---+---+---+---+---+---+---+
\______ _____/ i \______ _____/
\/ \/
<=a[i] >=a[i] (a[i] ist das Pivot-Element)
i ← partition(l,r) ← {
p ← a[r] #p: Pivot-Element. Hier wird willkürlich das rechteste
# Element als Pivot-Element genommen.
i ← l-1 #i und j sind Laufvariablen
j ← r
repeat
repeat
i ← i+1 #Finde von links den ersten Eintrag >= p
until a[i] >= r
repeat
j ← j-1 #Finde von rechts den ersten Eintrag < p
until a[j] <= r
swap(a[i], a[j])
until j <= i #Nachteile: p steht noch rechts
swap(a[i], a[j]) #Letzter Austausch zwischen i und j muss
#zurückgenommen werden
swap(a[i], a[r]) #Das Pivot-Element wird an die korrekte Position gesetzt.
return(i)
}
p
+---+---+---+---+---+---+---+---+---+
Array: | | | | |\\\| | | | |
+---+---+---+---+---+---+---+---+---+
-------> i>p j<p <-------
| |
+---------------+
Diese zwei Elemente werden ausgetauscht.
p
+---+---+---+---+---+---+---+---+---+
Array: | | | | |\\\| | | | |
+---+---+---+---+---+---+---+---+---+
-----------------> <-----------------
"repeat" bis sich die Zeiger treffen oder einander überholt haben.
l,i --> <-- j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | S | O | R | T | I | N | G | E | X | A | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | S | O | R | T | I | N | G | E | X | A | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i j r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | O | R | T | I | N | G | E | X | S | M | P | L | E |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
j i r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | R | E | T | I | N | G | O | X | S | M | P | L | E | --> Hier wird die
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+ Schleife verlassen.
j i r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | E | R | T | I | N | G | O | X | S | M | P | L | E | 1.swap
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
i r
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| A | A | E | E | T | I | N | G | O | X | S | M | P | L | R | 2.swap
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
- Bemerkungen zur gegebenen Implementierung:
- Die gegebene Implementierung benötigt ein Dummy-Minimalelement (für den Fall i=1).
- Dieses Element ist durch zusätzliche if-Abfrage vermeidbar, aber die if-Abfrage erhöht die Komplexität des Algorithmus (schlechte Performanz).
- Sie ist uneffizient für (weitgehend) sortierte Arrays, da sich folgende Aufteilung für die Partitionen ergibt:
- Erste Partition: [l,i-1], zweite Partition: [i+1,r]
- Die erste Partition umfasst N-1 Elemente. Die zweite Partition ist leer (bzw. sie existiert nicht), weil das Pivot-Element p = r gewählt wurde.
- Das Array wird elementweise abgearbeitet. → N einzelne Aufrufe ⇒ Zeitkomplexität:
 .
.
- Für identische Schlüssel sollten beide Laufvariablen stehen bleiben (daher ""), um ausgeglichene Zerlegungen bei vielen identischen Schlüsseln zu gewährleisten.
- Bei der gegebenen Implementierung tauscht auch gleiche Elemente aus.
- Für identische Schlüssel können die Abbruchbedingungen verbessert werden (siehe Sedgewick, Seite 150).
c) Komplexität
![C(N) = (N+1) + \frac{1}{N} \sum_{k=1}^{N} \left[ C(k-1) + C(N-k) \right]](/images/math/c/c/b/ccb8bc97d5005caa14d9fb9ab5861d07.png) für
für 
Anmerkungen zur Formel:
-
 : Vergleiche für jeden Aufruf
: Vergleiche für jeden Aufruf -
 : Teilungspunkt
: Teilungspunkt -
![\frac{1}{N} \sum_{k=1}^{N} \left[ C(k-1) + C(N-k) \right] = 2 \frac{1}{N} \sum_{k=1}^{N} C(k-1)](/images/math/d/4/4/d441dcff585e15d5779fc23fdca6d344.png) ist der mittlere Aufwand über alle möglichen Zerlegungen.
ist der mittlere Aufwand über alle möglichen Zerlegungen.


![N \cdot C(N) = N \left[ (N+1) + \frac{2}{N} \sum_{k=1}^{N} C(k-1) \right] \overset{-\, (N-1) \cdot C(N-1)}{\longleftrightarrow}](/images/math/0/7/0/070ccdaaebf0c2701672935712a2665b.png)








Für sehr große N gilt:
 beziehungsweise
beziehungsweise 
Mittlere Komplexität:

d) Verbesserungen des Quicksort-Algorithmus
Beseitigung der Rekursion
- Eine Verbesserung beseitigt die Rekursion durch Verwendung eines Stacks. Nach jeder Partitionierung wird das größere Teilintervall auf dem Stack abgelegt und das kleinere Teilintervall direkt weiterverarbeitet.
quickSort(l,r) ← {
#initialize stack
push([l,r])
repeat
if r > l:
i ← partition(l,r)
if (i-l) > (r-i):
push([l,i-1])
l ← i+1
else:
push([i+1,r])
r ← i-1
else:
[l,r] ← pop()
until stackempty()
}
+---+---+---+---+---+---+---+
| Q | U | I | C | K | S | O |
+---+---+---+---+---+---+---+
+---+---+---+===+---+---+---+
| K | C | I |=O=| Q | S | U |
+---+---+---+===+---+---+---+
\_________/
push
+---+===+---+
| C |=I=| K |
+---+===+---+
\_/
push
+===+
|=C=|
+===+
+===+
|=K=|
+===+
+---+---+===+
| Q | S |=U=|
+---+---+===+
+---+===+
| Q |=S=|
+---+===+
+===+
|=Q=|
+===+
+---+---+---+---+---+---+---+
| C | I | K | O | Q | S | U |
+---+---+---+---+---+---+---+
Alternatives Sortieren kleiner Intervalle
- Für kleine Intervalle ist Insertion Sort effizienter als "Teile und herrsche"
- Modifikation:
if (r-l) <= K:
insertion(l,r)
else:
#wie bisher
- für M = 3: explizites Sortieren von 3 Elementen. - Sortieren von 3 Datensätzen. Idee:
- Stelle sicher, dass a[1] und a[2] relativ zueinander sortiert sind.
- Falls a[1] jetzt noch größer als a[3] ist, so ist a[3] das kleinste Element und muss nach vorne geschrieben werden. Das heißt: swap(a[i], a[3]). Danach steht das kleinste Element in a[1].
- Jetzt kann es entweder sein, dass
- in 2. kein swap durchgeführt wurde und a[3] eventuell zwischen a[1] und a[2] liegen könnte, oder
- der swap durchgeführt wurde und die Reihenfolge von a[2] und a[3] jetzt falsch ist.
- Falls a[2] > a[3], dann swap(a[2], a[3]). Das löst beide in 3. genannten Probleme.
- Der Algorithmus zum Sortieren von drei Datensätzen:
a = sort2(a) ← {
if a[1] > a[2]:
swap(a[1], a[2])
if a[1] > a[3]:
swap(a[1], a[3])
# Man könnte hier
# swap(a[2],a[3])
# return
# einfügen und eine if-Abfrage sparen.
if a[2] > a[3]:
swap(a[2], a[3])
}
Günstige Selektion des Pivot-Elements
- Das Pivot-Element könnte geschickter gewählt werden. Methode: Median von drei Elementen: Bestimme den Median der ersten, mittleren und letzten Elements eines Arrays und verwende der Median als Pivot-Element
- Diese Methode minimiert die Häufigkeit des Auftetens des ungünstigsten Falles.
147.142.207.188 19:31, 23 April 2008 (UTC)